Construindo Rag Com Laravel
Venho estudando ultimamente sobre IA: como fazer prompts mais eficientes, como construir um RAG e como fazer um fine-tuning de um modelo de IA. E, para que eu possa fixar mais o meu conhecimento, resolvi criar um projeto com Laravel onde eu possa praticar de forma mais concreta. Ainda mais que, nos dias de hoje, só se fala sobre IA, mas não vejo muito conteúdo em português falando sobre como criar RAG com PHP.
Meu objetivo com esse post é criar um RAG bem simples, onde eu possa mostrar detalhe por detalhe todo o processo de criação. Seria um projeto básico, mas que vai servir de base para posts futuros. Quero, aos poucos, implementar novos recursos nesse projeto e registrar os passos que eu fizer.
Então, sem mais delongas, vamos iniciar!
O que é RAG?
RAG (Retrieval-Augmented Generation) é uma técnica utilizada para aumentar a qualidade das respostas de um modelo de IA. Com essa técnica, você pode ampliar a quantidade de informações que o seu modelo pode utilizar.
Utilizamos RAG quando precisamos de informações específicas e atualizadas, como ler documentação de uma empresa, acessar dados em um banco de dados ou, por exemplo, em um sistema de suporte. Caso não utilizemos essa técnica, o modelo pode gerar alucinações ou inconsistências nas respostas.
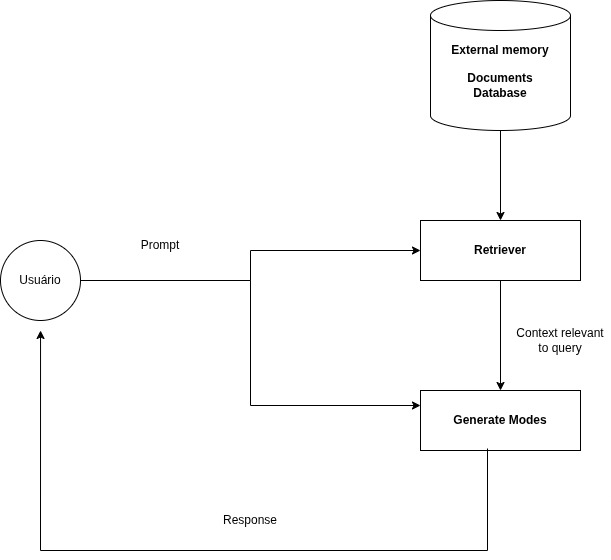
Preparando o ambiente
Para dar sequência ao nosso projeto, precisamos instalar o Laravel e o ollama-php. Primeiro, faremos a instalação do Laravel usando o Composer:
composer create-project laravel/laravel rag-laravel
cd rag-laravel Depois que fizemos a instalação do Laravel, instalamos o arda-ollama. Esse pacote é uma biblioteca que permite acessar o Ollama diretamente pelo PHP.
composer require ardagnsrn/ollama-phpJá que estamos com o Laravel e o pacote devidamente instalados, iremos instalar o Ollama e rodar um modelo. Para este exemplo, estou usando o modelo qwen2.5:1.5b, no sistema operacional Ubuntu 22.04 e utilizando arquivo markdown.
Caso você esteja usando outro sistema operacional, recomendo acessar o site do Ollama e seguir as instruções de instalação: https://ollama.com/download
Execute o comando abaixo para instalar o Ollama:
curl -fsSL https://ollama.com/install.sh | shApós a instalação do Ollama, vamos rodar o modelo. Para isso, usamos o comando para fazer o pull do modelo:
ollama pull qwen2.5:1.5bA escolha do modelo qwen2.5:1.5b foi feita porque a maioria das pessoas não possui um computador muito robusto, e esse modelo tende a rodar melhor em máquinas com menos recursos. Por outro lado, como ele é menor, pode demorar um pouco mais para responder e sua qualidade pode ser inferior quando comparado a modelos maiores.
Indexando os documentos
Agora, com tudo praticamente configurado, é hora de colocar a mão na massa. Primeiro, vamos ler os documentos que serão usados no nosso RAG e, em seguida, criar embedding para cada um deles e salvar no banco de dados.
Mas antes de iniciar, é importante entender como funcionam os embedding e por que eles são necessários. A técnica de embedding nos permite representar textos de forma que o modelo consiga compreender melhor o seu significado.
Se, por exemplo, enviarmos um livro muito grande diretamente para o modelo, a quantidade de informação pode ser tão grande que ele pode acabar gerando respostas diferentes do que esperamos. Por isso, criamos um embedding para cada arquivo (e, se necessário, dividimos o texto em chunks para melhorar a precisão) e armazenamos esses embedding no banco.
Quando o usuário faz uma pergunta, essa pergunta também é convertida em um embedding. O sistema então faz um cálculo de similaridade entre o embedding da pergunta e os embedding armazenados no banco de dados, retornando os trechos mais relevantes para construir a resposta.
Agora, entre no diretório do projeto e vamos criar um comando no Laravel para gerar os embedding.
php artisan make:command embedding
Antes de começar a criar embedding com ferramentas mais avançadas, como o modelo qwen2.5:1.5b-embedding, é interessante entendermos primeiro o conceito de embedding de forma simples. Para ilustrar isso, podemos criar uma função básica em PHP e adicionar no arquivo criado anteriormente:
private function gerarembeddingimples(string $texto): array
{
// Quebra o texto em palavras únicas e ordenadas
$palavras = array_unique(str_word_count(strtolower($texto), 1));
sort($palavras);
// Cria um hash numérico simples (mock de embedding)
return array_map(fn($p) => crc32($p) % 1000 / 1000, $palavras);
}Entendendo passo a passo
- Normalização do texto:
O código transforma tudo em minúsculas e quebra em palavras únicas.
$palavras = array_unique(str_word_count(strtolower($texto), 1));Isso garante que “PHP” e “php” sejam tratados como a mesma palavra.
- Ordenação:
Assim o resultado é previsível — duas frases com as mesmas palavras terão o mesmo “embedding”.
sort($palavras);- Criação do vetor numérico:
array_map(fn($p) => crc32($p) % 1000 / 1000, $palavras);Cada palavra é transformada em um número usando crc32. Esse número é reduzido para algo entre 0 e 1 — simulando o comportamento de um embedding real, que também é uma lista de números flutuantes.
- Resultado:
Com isso, teremos algo parecido com o seguinte:
[0.234, 0.678, 0.912]Adicione o código abaixo dentro do comando embedding, nesse código informamos o diretório onde ficam nossos documentos, geramos o embedding de cada arquivo e salvamos tudo no banco de dados.
public function handle(): void
{
$arquivos = glob('/var/www/projeto/ollama-php/docs/*.md');
foreach ($arquivos as $arquivo) {
$conteudo = file_get_contents($arquivo);
$this->info($arquivo);
$embedding = $this->gerarembeddingimples($conteudo);
DB::table('documents_embedding')->insert([
'filename' => basename($arquivo),
'content' => $conteudo,
'embedding' => json_encode($embedding),
]);
}
}Exemplo completo do comando embedding:
<?php
namespace App\Console\Commands;
use Illuminate\Console\Command;
use Illuminate\Support\Facades\DB;
class embedingsCommand extends Command
{
protected $signature = 'embedings';
protected $description = 'Command description';
public function handle(): void
{
$arquivos = glob('/var/www/projeto/ollama-php/docs/*.md');
foreach ($arquivos as $arquivo) {
$conteudo = file_get_contents($arquivo);
$embedding = $this->gerarembeddingimples($conteudo);
DB::table('documents_embedding')->insert([
'filename' => basename($arquivo),
'content' => $conteudo,
'embedding' => json_encode($embedding),
]);
}
}
private function gerarembeddingimples(string $texto): array
{
// Quebra o texto em palavras únicas e ordenadas
$palavras = array_unique(str_word_count(strtolower($texto), 1));
sort($palavras);
// Cria um hash numérico simples (mock de embedding)
return array_map(fn($p) => crc32($p) % 1000 / 1000, $palavras);
}
}Buscando o contéudo por similaridade
Agora que temos os documentos embedados no banco de dados, é hora de realizar a busca. Mas, antes disso, precisamos criar uma função para calcular a similaridade entre dois embedding.
O que é similaridade?
É uma medida que indica o quanto dois textos, frases, palavras ou vetores são semelhantes. Ela não compara apenas letras ou palavras idênticas, mas sim o sentido e a estrutura do texto.
Exemplo:
Texto A: "O gato está dormindo no sofá"
Texto B: "Um felino descansa no sofá"
Eles são diferentes em palavras, mas muito semelhantes em significado.
Um modelo de embedding (como os usados em RAG) gera vetores que ficam próximos uns dos outros no espaço vetorial quando os textos possuem significados semelhantes. Quando isso acontece, a similaridade entre esses vetores será alta — por exemplo, 0.92 em uma escala de 0 a 1.
Nosso trecho de código da função similaridade:
private function similaridade(array $a, array $b): float
{
$inter = count(array_intersect(array_keys($a), array_keys($b)));
return $inter / max(count($a), count($b));
}Entendendo passo a passo
- Pegamos apenas as chaves dos dois arrays.
array_keys($a) e array_keys($b)- Retorna a interesençao do array:
array_intersect(array_keys($a), array_keys($b))- Conta a quantidade de palavras.
count(array_intersect(array_keys($a), array_keys($b)));- Calcula a proporção de chaves que são iguais entre os dois arrays:
$inter / max(count($a), count($b));O resultado é um número entre 0 e 1, onde valores mais próximos de 1 indicam maior similaridade.
Criando o chat
Executamos o comando abaixo para criar o chat:
php artisan make:command chat-testCopie e cole o código abaixo no arquivo criado:
<?php
namespace App\Console\Commands;
use Illuminate\Console\Command;
use Illuminate\Support\Facades\DB;
use function Laravel\Prompts\textarea;
use function Laravel\Prompts\select;
class chatCommand extends Command
{
protected $signature = 'chat-test';
protected $description = 'Command description';
public function handle()
{
$client = \ArdaGnsrn\Ollama\Ollama::client();
$pergunta = textarea('Escreva aqui');
$embeddingPergunta = $this->gerarembeddingimples($pergunta);
// Carrega embedding do banco
$documentos = DB::table('documents_embedding')->get();
$ranked = [];
foreach ($documentos as $doc) {
$emb = json_decode($doc->embedding, true);
$ranked[$doc->id] = $this->similaridade($embeddingPergunta, $emb);
}
// Ordena por similaridade
arsort($ranked);
// Pega os 3 melhores
$topDocs = collect(array_keys($ranked))->take(3)
->map(fn($id) => $documentos->firstWhere('id', $id))
->pluck('content')
->implode("\n\n");
// Monta o prompt com o contexto combinado
$prompt = "Você é um assistente que responde apenas com base no conteúdo abaixo.
Se a resposta não estiver presente no conteúdo, diga: 'Desculpe, a resposta para essa pergunta não está disponível neste documento.'.\n\n" .
"---\n" . $topDocs . "---\n\n" .
"Pergunta: $pergunta";
$response = $client->chat()->create([
'model' => 'qwen2.5:3b',
'messages' => [
['role' => 'user', 'content' => $prompt],
],
]);
$resultado = $response->message->content; // 'Ah, taxes... *chew chew* Hmm, not really sure how to help with that.';
dd($resultado);
}
// Calcula similaridade (cosine-like simplificado)
private function similaridade(array $a, array $b): float
{
$inter = count(array_intersect(array_keys($a), array_keys($b)));
return $inter / max(count($a), count($b));
}
private function gerarembeddingimples(string $texto): array
{
// Quebra o texto em palavras únicas e ordenadas
$palavras = array_unique(str_word_count(strtolower($texto), 1));
sort($palavras);
// Cria um hash numérico simples (mock de embedding)
return array_map(fn($p) => crc32($p) % 1000 / 1000, $palavras);
}
}Como o código acima pode ser um pouco complicado, vou explicar o passo a passo:
Entendendo passoa a passo
- Instanciamos o cliente que vamos usar para conectar ao Ollama:
$client = \ArdaGnsrn\Ollama\Ollama::client();- Criamos um textarea para que o usuário digite a pergunta:
$pergunta = textarea('Escreva aqui');- Criamos o embedding da pergunta, para que possamos fazer o cálculo da similaridade
$embeddingPergunta = $this->gerarembeddingimples($pergunta);- Trazemos os documentos embedados do banco de dados e armazenamos em uma variável:
$documentos = DB::table('documents_embedding')->get();- Agora fazemos o cálculo de similaridade entre o embedding da pergunta e os embedding dos arquivos do banco. Em seguida, adicionamos no array o id do documento e o resultado da similaridade.
$ranked = [];
foreach ($documentos as $doc) {
$emb = json_decode($doc->embedding, true);
$ranked[$doc->id] = $this->similaridade($embeddingPergunta, $emb);
}- Ordenamos pela similaridade:
arsort($ranked);- Agora fazemos um filtro trazendo somente os 3 melhores.
$topDocs = collect(array_keys($ranked))->take(3)
->map(fn($id) => $documentos->firstWhere('id', $id))
->pluck('content')
->implode("\n\n");- Montamos o prompt combinando o prompt do sistema + o prompt escrito pelo usuário + o contexto, que nada mais é do que os arquivos que buscamos no passo 7:
$prompt = "Você é um assistente que responde apenas com base no conteúdo abaixo.
Se a resposta não estiver presente no conteúdo, diga: 'Desculpe, a resposta para essa pergunta não está disponível neste documento.'.\n\n" .
"---\n" . $topDocs . "---\n\n" .
"Pergunta: $pergunta";- Agora vamos criar o model e passar o prompt para o modelo, para que ele possa gerar a resposta:
$response = $client->chat()->create([
'model' => 'qwen2.5:3b',
'messages' => [
['role' => 'user', 'content' => $prompt],
],
]);- Agora pegamos a resposta e mostramos no console:
$resultado = $response->message->content;
$this->info($resultado);Rodando via comando o RAG
Primeiramente, vamos criar uma tabela no banco de dados para armazenar os embedding:
Arquivo do migrate para criar a tabela:
<?php
use Illuminate\Database\Migrations\Migration;
use Illuminate\Database\Schema\Blueprint;
use Illuminate\Support\Facades\Schema;
return new class extends Migration {
public function up(): void
{
Schema::create('documents_embedding', function (Blueprint $table) {
$table->id();
$table->string('filename');
$table->text('content');
$table->json('embedding'); // array de floats
$table->timestamps();
});
}
public function down(): void
{
Schema::dropIfExists('documents_embedding');
}
};Rodamos o comando para criar a tabela:
php artisan migrateAgora, com o nosso código finalizado, podemos rodar o comando para ver o resultado. Primeiro, executamos o comando responsável por inserir os embedding no banco de dados:
php artisan embbedingDepois com os arquivos inseridos no banco de dados, podemos executar o comando do chat:
php artisan chatPodemos digitar a pergunta e ver o resultado.
Observações
Nos meus testes, fiz algumas perguntas em que o modelo demorou bastante para responder, pois estamos usando um modelo bem simples, apenas para ilustrar o funcionamento do RAG.
Algumas perguntas ele não conseguiu responder com base no documento, mas isso já era esperado. Mesmo criando embedding, o arquivo ainda pode ser grande demais para o modelo interpretar, o que pode gerar inconsistências ou até alucinações na resposta.
Para que possamos resolver isso, temos alguns passos que podemos seguir para tentar melhorar o modelo:
- Criar chunks de cada arquivos, usar alguma estratégia e cada arquivo nós separarmos por chunks de 500 palavras ou 1000
- Melhorar nosso prompt do sistema que enviamos juntos com o contexto e a pergunta do usuário.
- Fazer Fine-tuning do modelo para melhorar o resultado.
Enfim, ainda temos muito para evoluir e melhorar no nosso modelo, mas com o passar do tempo vamos aprendendo e ajustando. Esses são assuntos que vamos abordar nos próximos posts.
Para não perder as próximas publicações, você pode me seguir nas redes sociais.
Link do projeto: https://github.com/dtgfranca/simple-rag-with-laravel
💬 Comentários